Improving Content Discovery Through Semantic Publishing and IPTC Metadata Standards

Organizations often have multiple systems and teams that author content. There can be a wide variety of content from photos, videos, articles and even sports statistics. The content created by these teams is high value and can often be used on multiple distribution channels. For example, content can be presented on your website, posted to social media or even be licensed to third parties.
The challenge is that each of these systems often author content in their own proprietary formats and organizational patterns. This causes issues around data discovery. One methodology is to leverage semantic publishing. Semantic publishing includes semantic markup and content for better discoverability, packaging and distribution. Standards published by the IPTC accelerate the development of a Semantic Publishing platform by providing containers and organization systems for your content.
What Is the IPTC?
The IPTC is a global standards body that has been active since the 1970s. Their goal is to develop and promote standards that simplify the distribution and storage of information. The IPTC is supported by industry experts from leading news and media companies. There are designated working groups that continually develop and support these standards. Photo metadata, video metadata, news, statistics and standardized taxonomies such as Media Topics are all offered by the IPTC.
These standards can be leveraged quite effectively in a multi-model data platform such as Progress MarkLogic. The ability to load data as-is and harmonize it into the corresponding IPTC standard is a great first step to making your data more discoverable and distributable. With the help of Progress Semaphore, news and media companies can classify their content and extract valuable metadata that aligns with the IPTC standards.
Leveraging MarkLogic Data Hub with IPTC Standards
MarkLogic Data Hub allows you to bring in data in varying formats. For the following use case, we will bring in data from Wikinews for our demonstration.
Data Hub Central is a user interface that allows you to configure and test your configurations on top of MarkLogic Server. The ability to load, model and curate data are all available within this interface. Everything that is demonstrated in the UI can be programmatically run at an enterprise scale.
Data Hub - Loading and Discovery Data
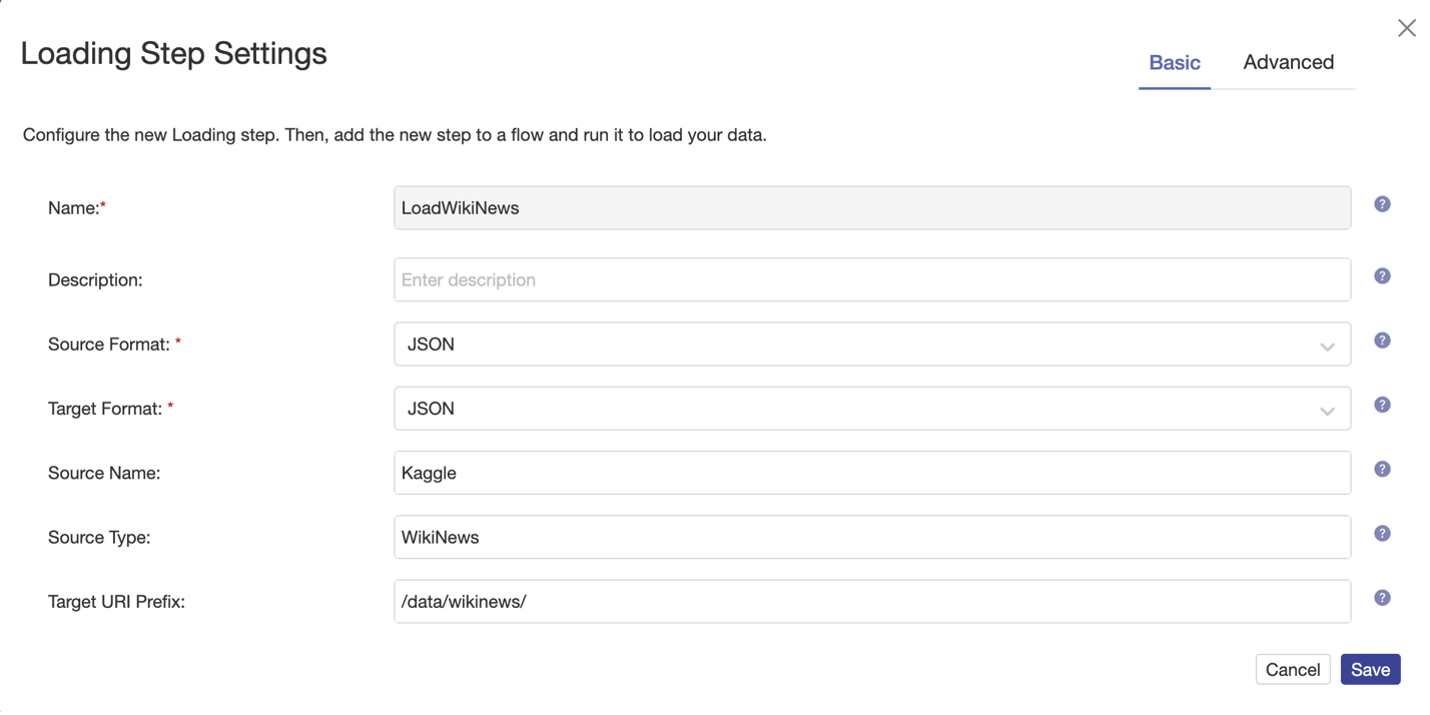
We will first load data from our first content system. In this case, we sourced an export of news articles from Wikinews in JSON format. MarkLogic can natively store multi-model data. This means that MarkLogic can store and index unstructured (Text, PDFs, Office Documents, etc.), semi-structured XML and JSON or fully structured (columns and rows) data. What is unique to MarkLogic is that you do not have to choose a type upfront. All these types can be stored and indexed in the same database.
In Data Hub Central we will configure a load step with a source and target of JSON. Importantly, we will add contextual metadata stating the source and source type. These properties will help with the discovery and clustering of data later.
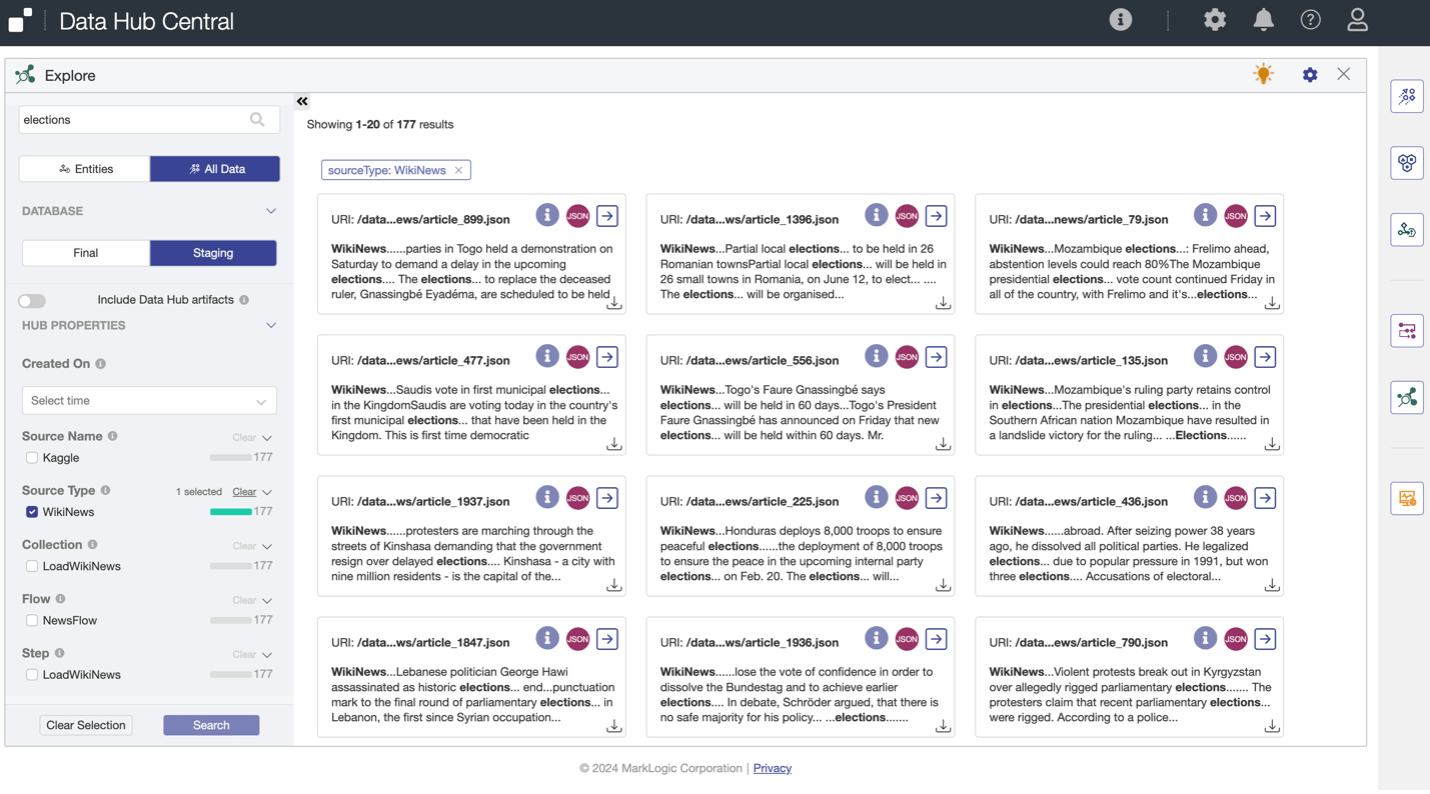
Once loaded, MarkLogic indexes the structure and text of the record. The Universal Index makes it instantly discoverable as part of the core transaction. We can explore this raw data with a Google-like search. In this example, we are looking for “elections” where the source type is Wikinews.
Data Hub - Modeling and Curation
While this raw data is useful, we would want to harmonize it into an interoperable standard. The IPTC ninjs (news in JSON) standard helps with defining a structure that can be leveraged for better interoperability and discovery.
“ninjs standardises the representation of news in JSON – a lightweight, easy-to-parse, data interchange format.” - IPTC
In Data Hub Central, we define an Entity Model under the Data Model tab. Here we can include strongly typed properties, nested structures and semantic relationships.
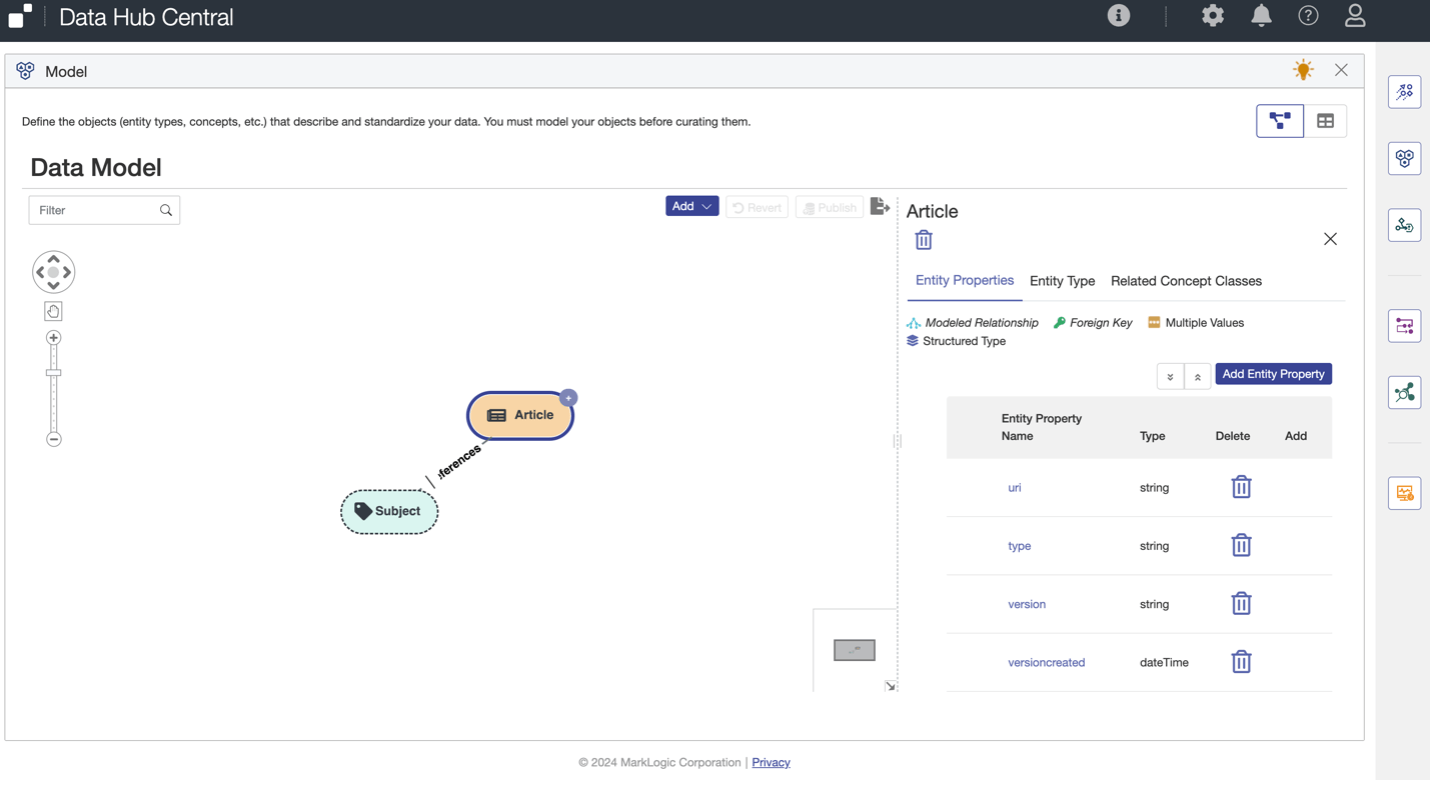
Data Hub Central also allows you to configure aggregations called facets and range indexes for sorting.
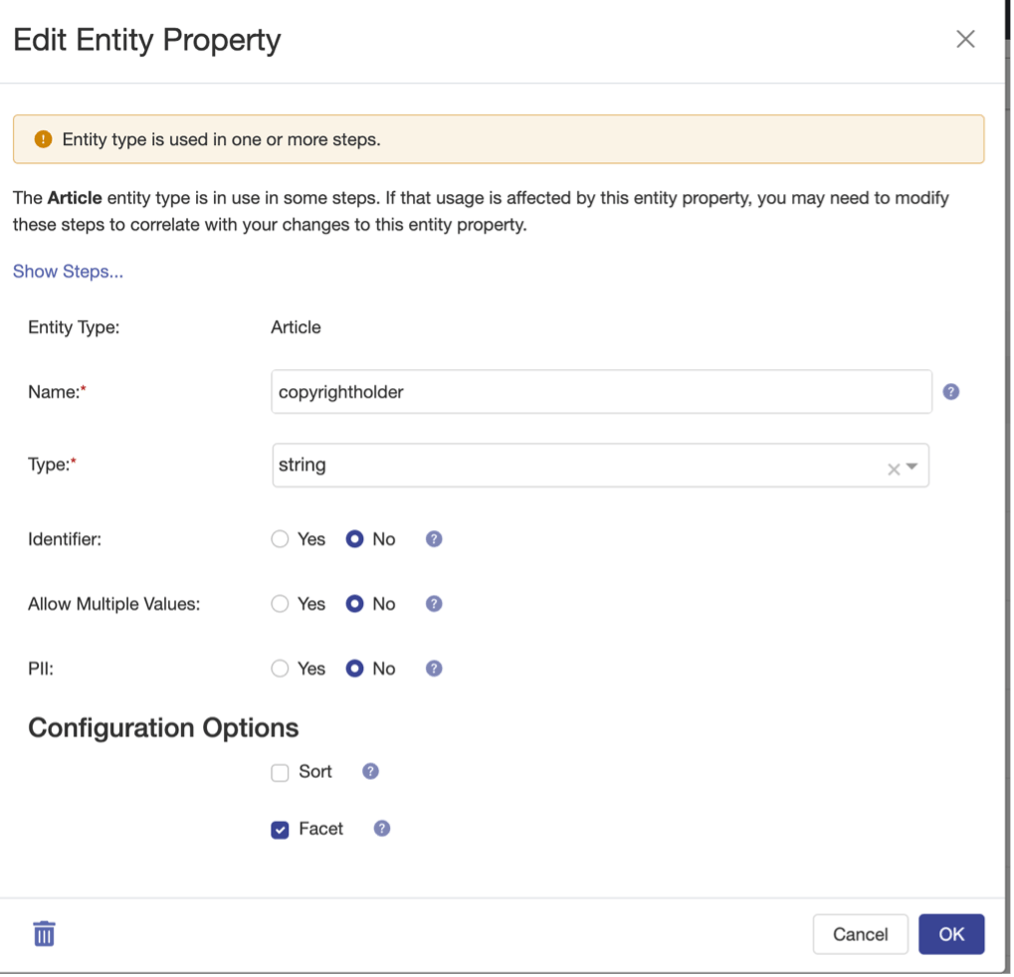
Once an Entity Model is defined, we will then curate the raw data into this model using the mapping tools. Looking at the Mapping tool offered by Data Hub Central we can use a configuration-based approach to transform data into our target standard.
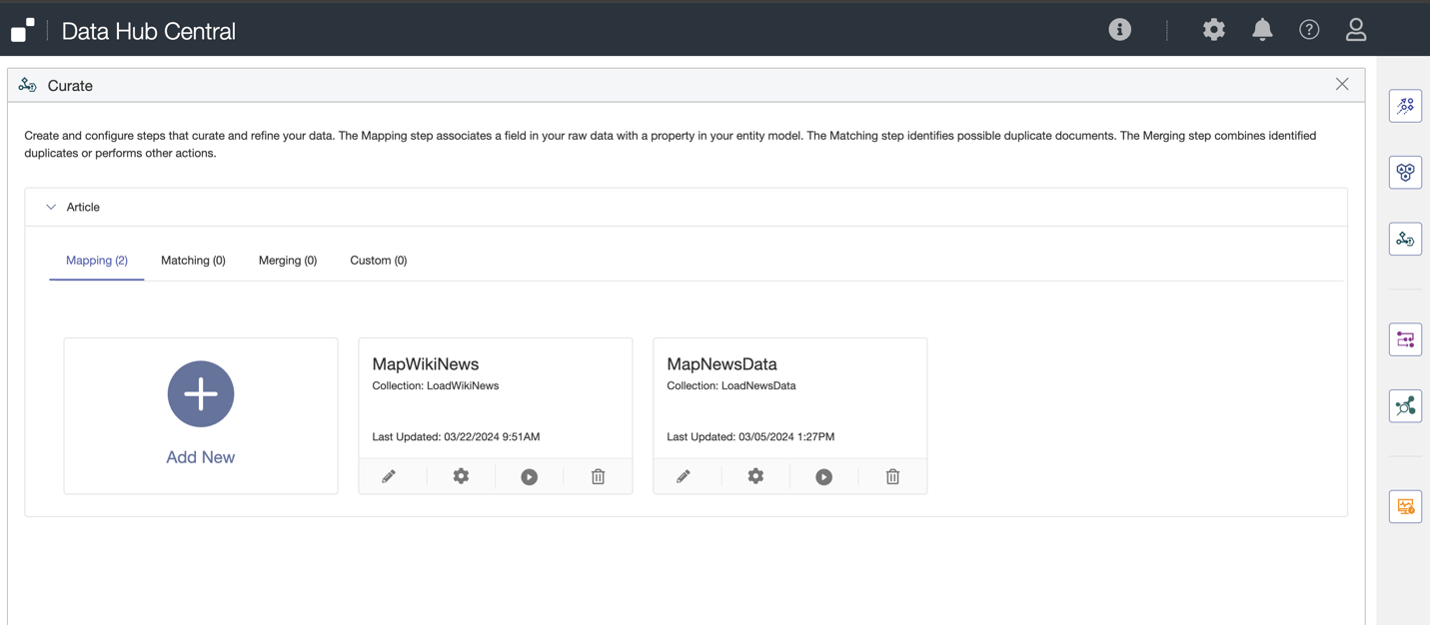
When defining a mapping step, you will define a source query or collection. We used “LoadWikinews” for the initial example.
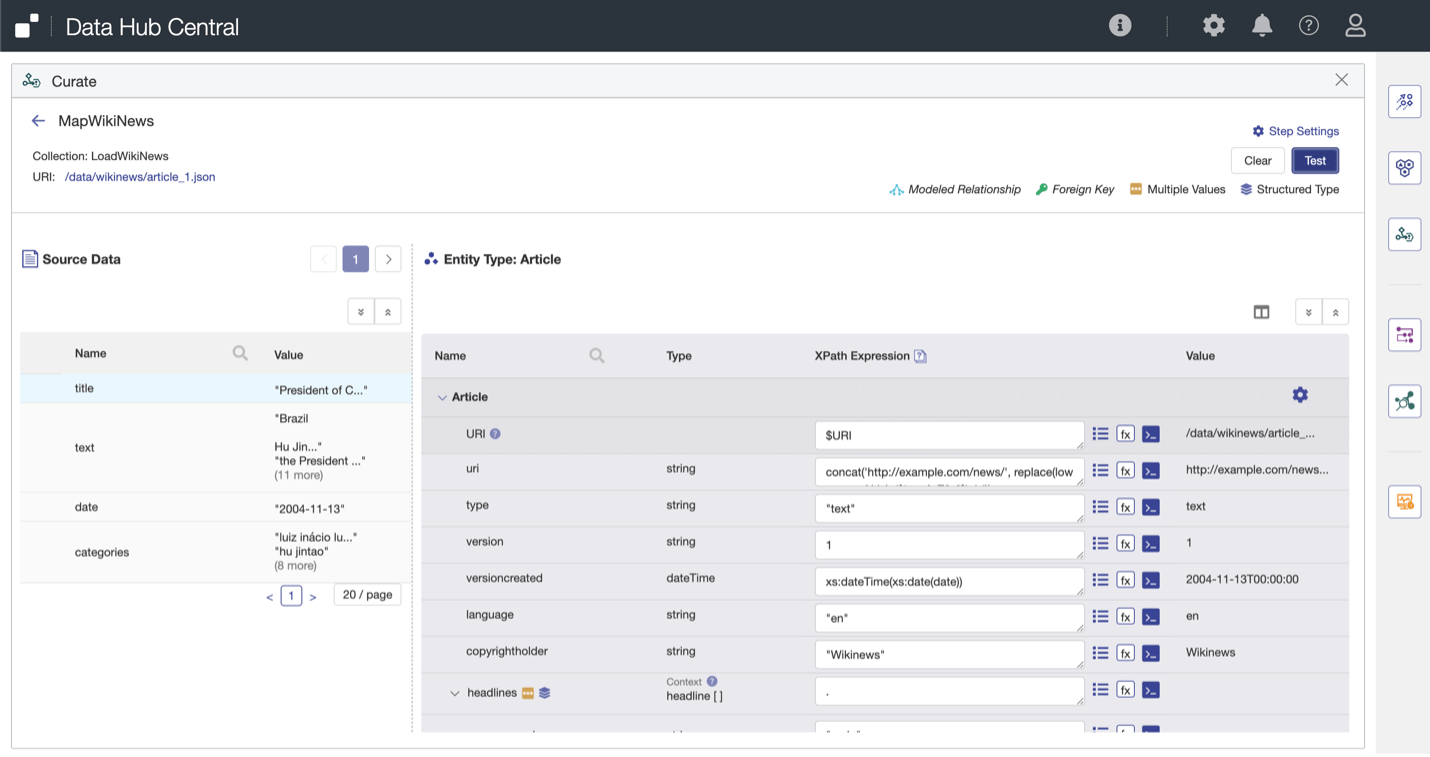
On the mapping screen, we see a sample document based on the query and the target Entity Model. We can then select paths in the original content, run clean-up using pre-defined functions, or define our own functions with server-side JavaScript or XQuery.
Once our mapping rules are defined, we can then test the mapping and run it at scale.
Now all our data will be discoverable in the defined Entity Model. We see our aggregates that were defined in the Entity Model and a structured view.
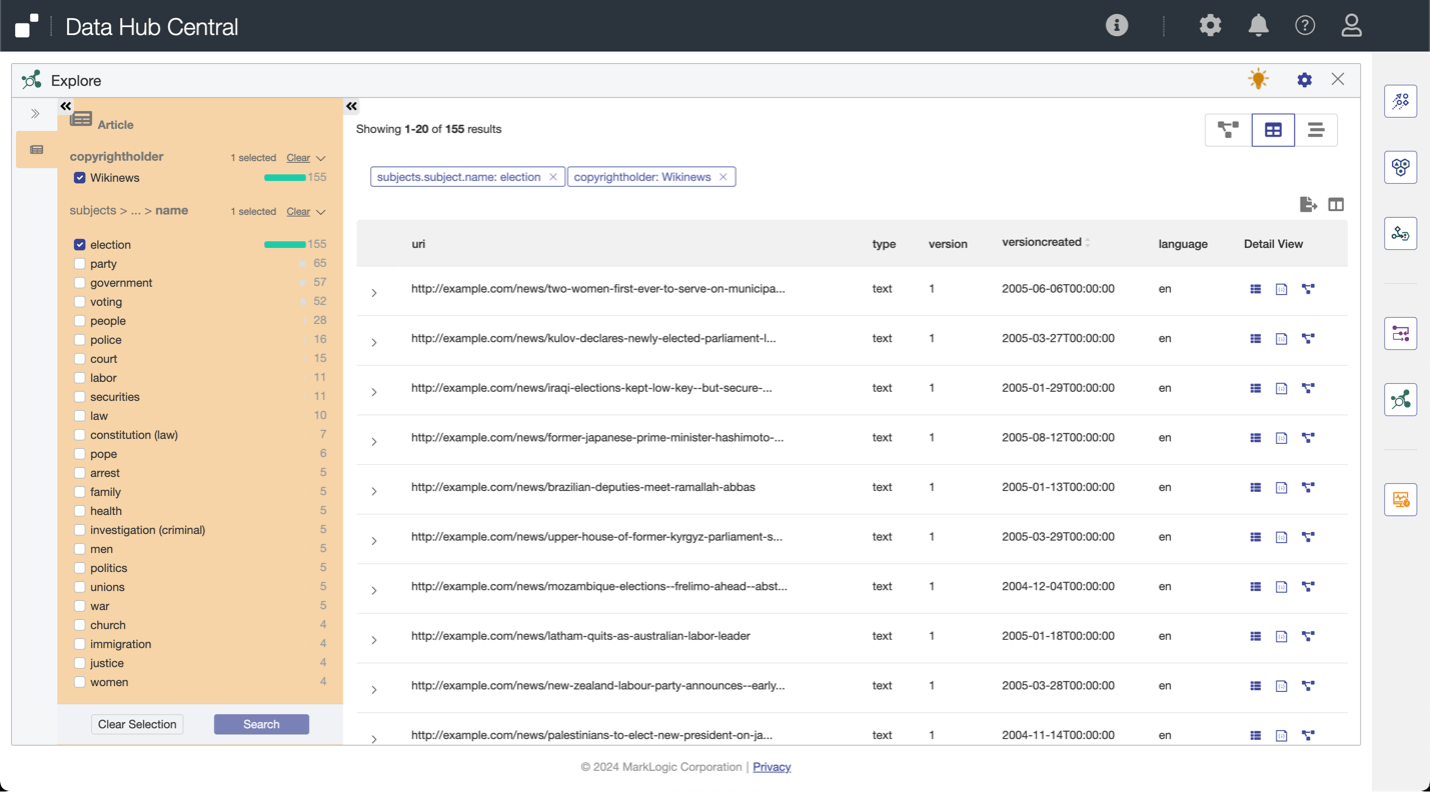
However, you see a new property called “subjects” that did not originate from the source content. This is where semantic analysis comes into play.
Semaphore - Semantic Models and Classification
Progress Semaphore is a semantic platform that empowers organizations to model their knowledge and harmonize it with standards information like IPTC. With that modeled information, Semaphore can automatically extract and classify structured and unstructured data, which can then be integrated across their technology architecture portfolio. Semaphore can be leveraged in conjunction with your Data Hub repository to classify and automatically tag content, resulting in enhanced search and retrieval experiences.
Semaphore leverages different knowledge organization systems like taxonomies, ontologies and controlled vocabularies to create Knowledge Models that can be shared and collaboratively built. Semaphore builds a semantic graph of concepts that can be leveraged across the enterprise. Hidden from the business user view, these concepts use OWL and SKOS/SKOS-XL information structures expressed as RDF triples to organize and manage concepts and schemes. These structures can be extended to meet your business needs as well.
The IPTC offers a robust categorization system that has multi-lingual support called Media Topics.
“Media Topics is a constantly updated taxonomy of over 1,200 terms with a focus on categorising text. Originally based on the IPTC Subject Codes taxonomy, the Media Topics taxonomy was first released in 2010 and is updated at least once a year. It is now available in 13 languages and language variants: Arabic, British and US English, Chinese, Danish, French, German, Norwegian (Bokmal and Nynorsk), Portuguese and Brazilian Portuguese, Spanish and Swedish.” - IPTC
The IPTC publishes the standard in RDF conforming to SKOS. Therefore, it can be easily loaded and managed in Semaphore. Do not worry if your organization does not have these formats. Concepts can easily be loaded from other formats such as spreadsheets and flat files.
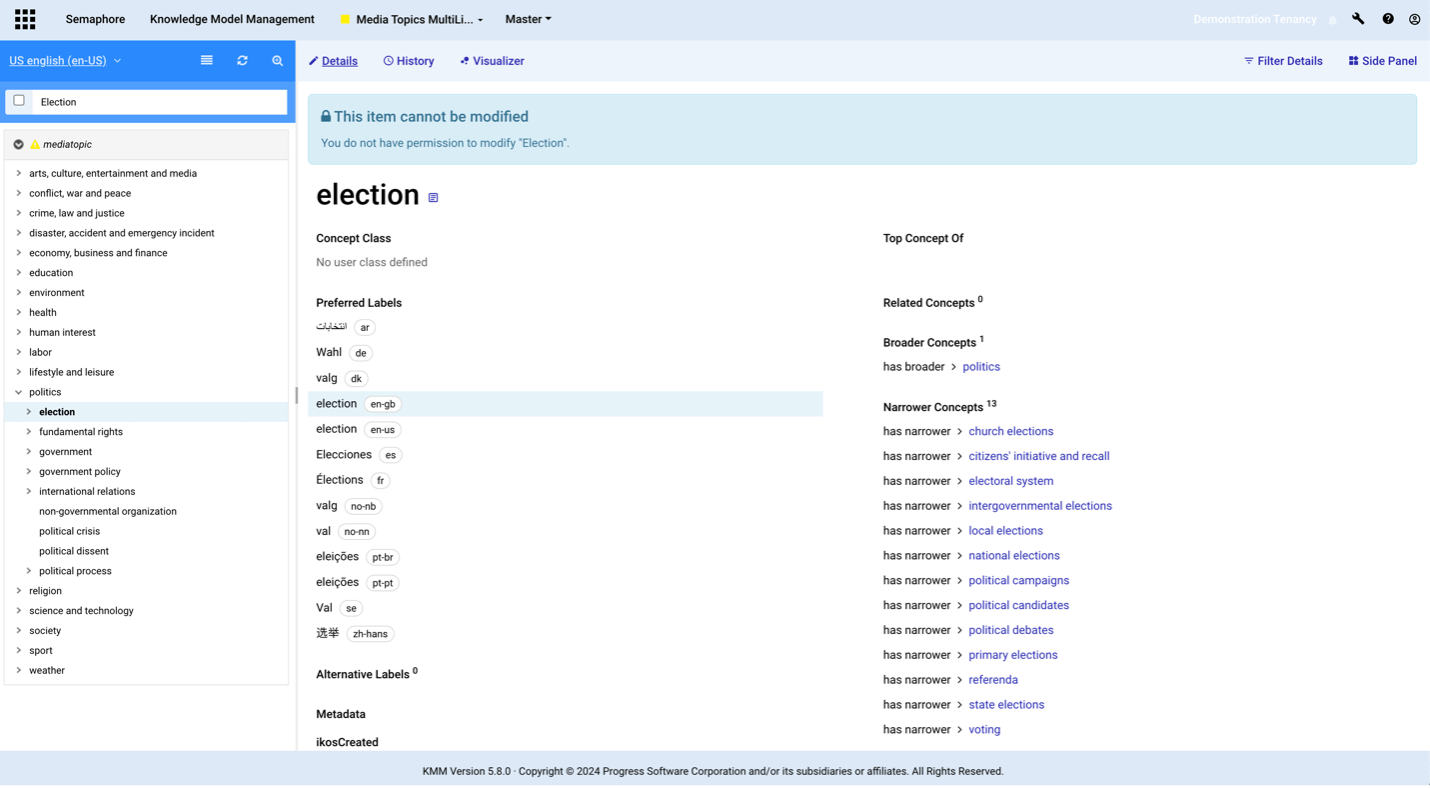
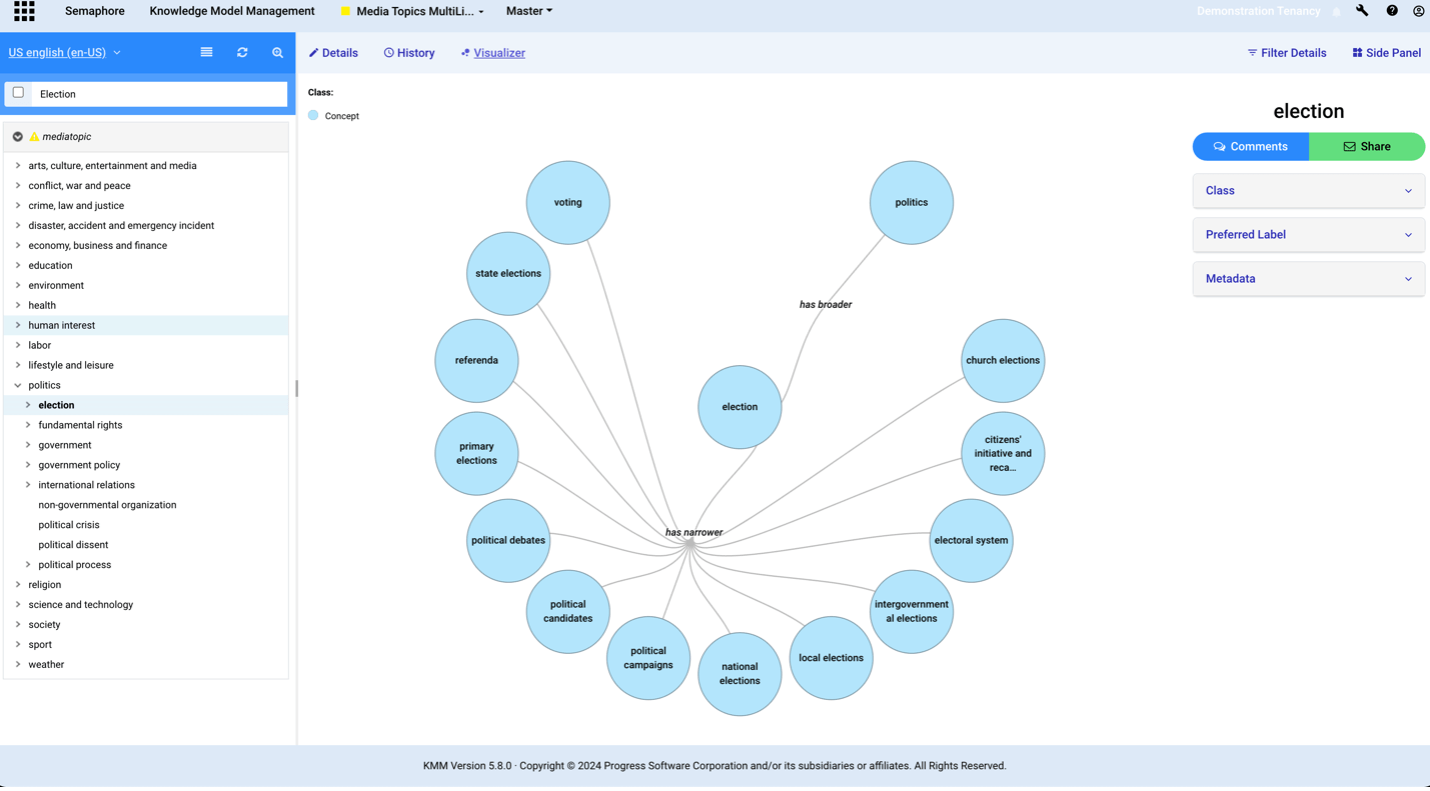
Here, the term election is displayed with its corresponding preferred labels and semantic relationships.
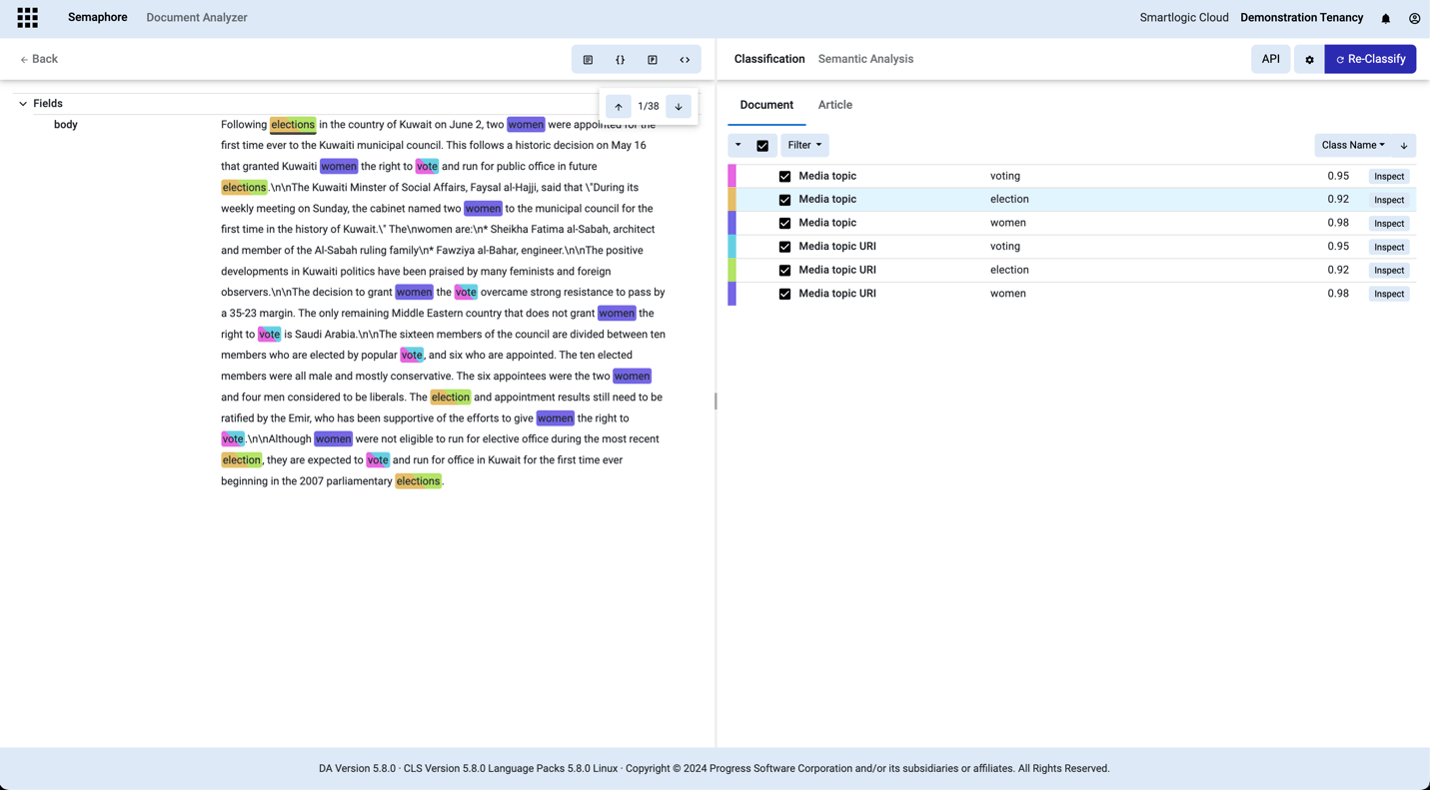
Once your Knowledge Model is ready, it can be published for use with the Semaphore Classification Service. This service analyzes text with NLP (Natural Language Processing) and the Knowledge Models to determine the aboutness of text while understanding key linguistic characteristics such as stemming, parts of speech and phrases. Semaphore will point you to the key concepts in the published Knowledge Model and the level of confidence it has calculated.
The Power of Connected Information
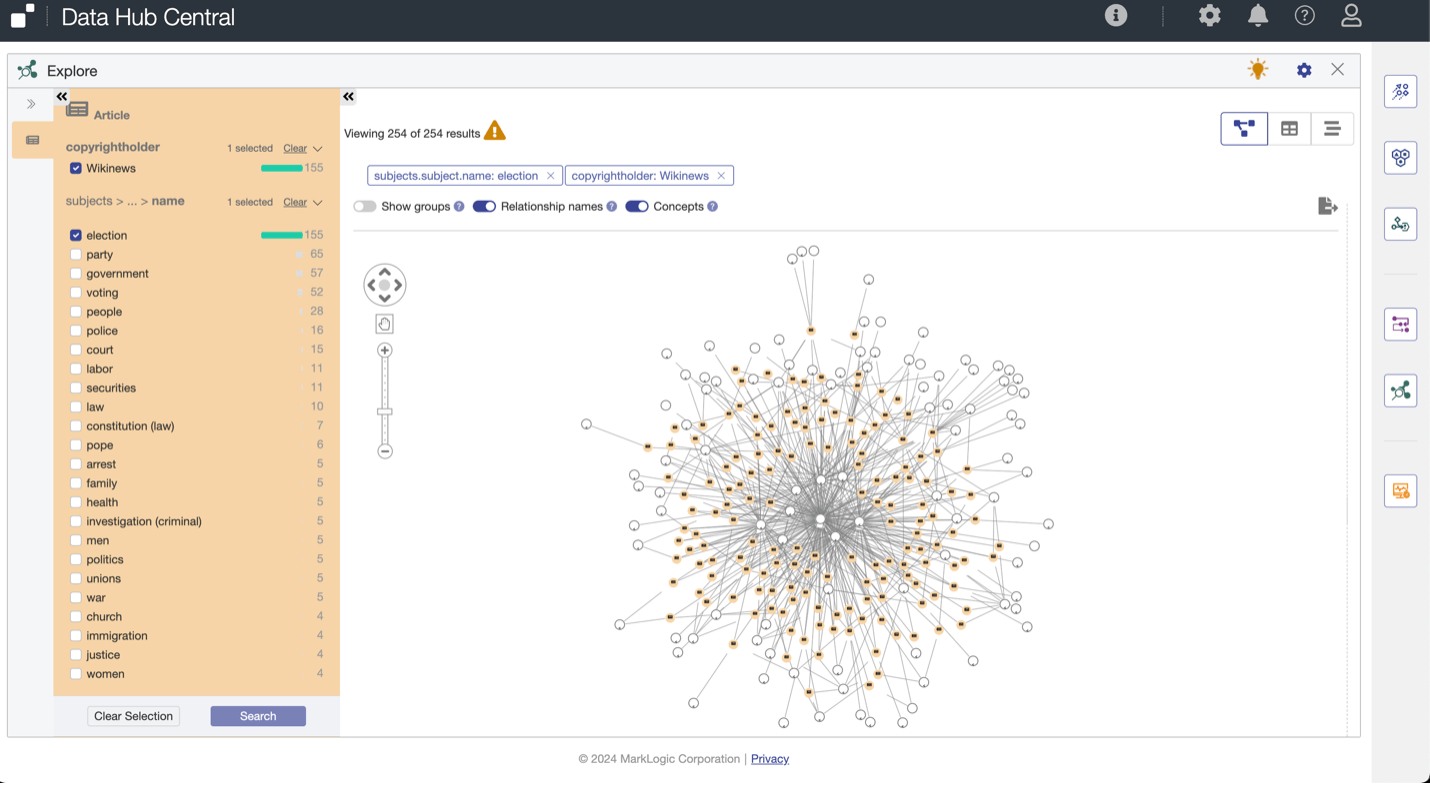
Now that the content is classified with Media Topics, and in the ninjs format, we can execute complex queries. This allows you to discover and package information with ease. We can traverse semantic relationships between the multiple articles and Media Topics. We can quickly aggregate and narrow down to a specific subject area. Or we can execute a mix-model query that uses article-free text search and the hierarchy of Media Topics using semantic expansion.
Conclusion
The ability to manage your information in a canonical format while allowing for robust data discovery is extremely valuable. A multi-model data platform like MarkLogic allows you to do this in a single repository with minimal configuration and development. Additionally, with Semaphore, you unlock additional insights that might have been lost in the sea of unstructured content. With the support of document management, search and semantic graphs in a single integrated platform you can focus on the key business objectives instead of learning and maintaining several technologies.
To find out more about our solutions, visit our website.

Drew Wanczowski
Drew Wanczowski is a Principal Solutions Engineer at MarkLogic in North America. He has worked on leading industry solutions in Media & Entertainment, Publishing, and Research. His primary specialties surround Content Management, Metadata Standards, and Search Applications.
Next:
Comments
Topics
- Application Development
- Mobility
- Digital Experience
- Company and Community
- Data Platform
- Security and Compliance
- Infrastructure Management
Sitefinity Training and Certification Now Available.
Let our experts teach you how to use Sitefinity's best-in-class features to deliver compelling digital experiences.
Learn MoreMore From Progress



Latest Stories
in Your Inbox
Subscribe to get all the news, info and tutorials you need to build better business apps and sites